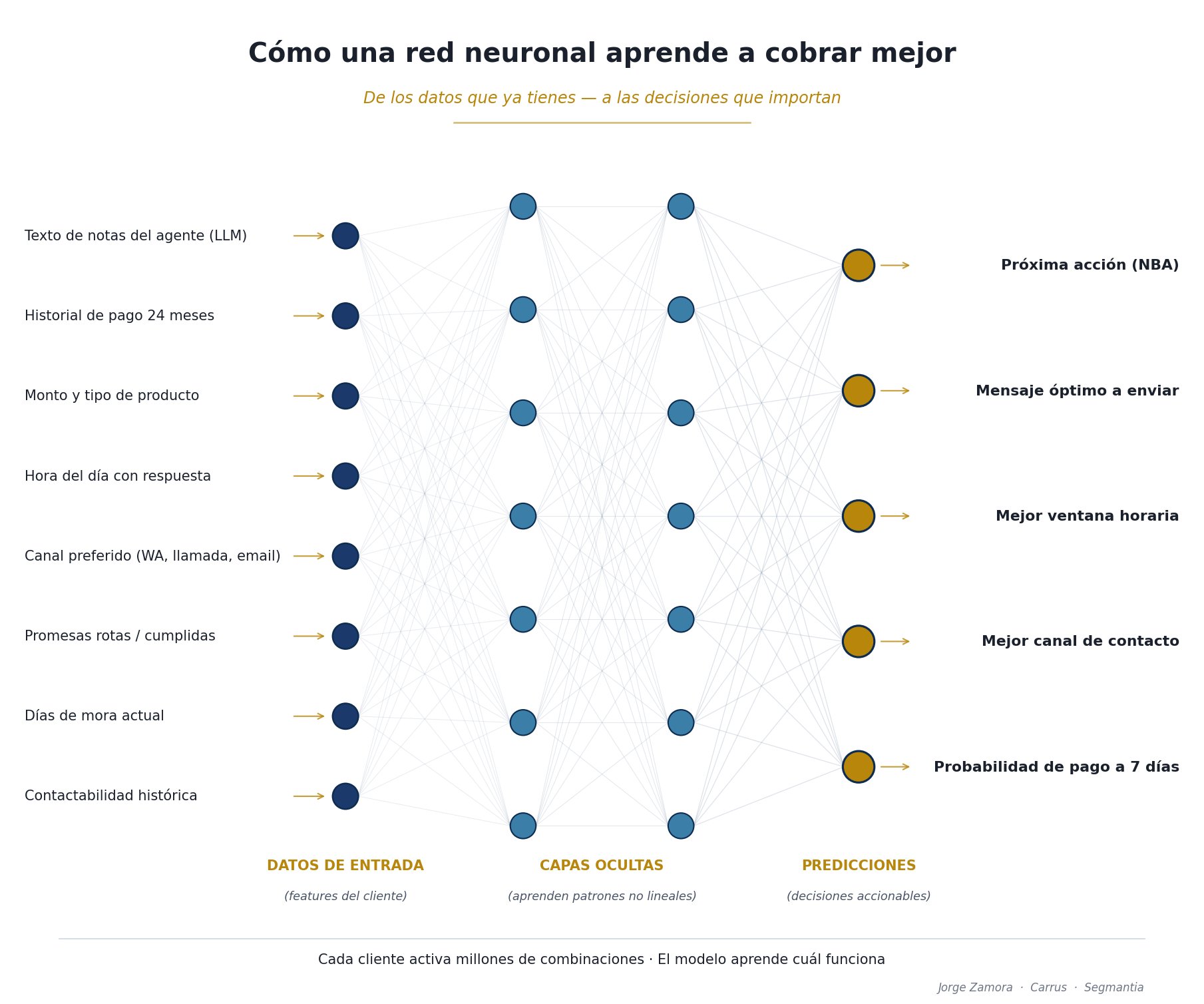
En cobranzas, la pregunta ya no es si tu modelo predice bien. Es si tu organización confía lo suficiente en él para usarlo.
El Data & AI Impact Report 2025 de SAS + IDC dejó tres datos que duelen para quienes trabajamos en banca y riesgo:
- Solo el 11% de los bancos tiene IA en la que confía internamente Y que además es demostrablemente confiable.
- 47% está atrapado en lo que IDC llama el "trust dilemma": subutilizan IA que sí funciona, o sobreutilizan IA que nadie validó.
- 78% dice confiar plenamente en su IA, pero solo 40% invirtió en gobernanza, explicabilidad y validación.
Traducción al pasillo del banco: pilotos de NBA (Next Best Action — la mejor próxima acción para cada cliente) y BTC (Best Time to Call — el mejor momento para llamar) que se estancan, comités que no firman el go-live, y modelos que terminan archivados porque "el negocio no los entendió". La confianza se rompe al primer mal lunes.
Por qué pasa esto
Las instituciones financieras están atrapadas en el día a día.
El call center necesita listas hoy. El comité de mora pide explicaciones de la semana pasada. La gerencia mide recupero mensual. Resultado: nos quedamos con árboles de decisión y reglas duras. "Si mora ≥ 30 y monto ≥ X, llamar a las 11 AM." Funciona. Pero rinde cada vez menos.
Por qué la segmentación con árboles ya no es suficiente
Un árbol (CART, Random Forest, incluso un XGBoost bien tuneado) divide tu cartera en grupos homogéneos y aplica una política a cada uno. Eso era frontera hace 10 años. Hoy es piso, no techo.
Sus límites en cobranzas:
- Saturan rápido. Más datos no mejoran el desempeño después de cierto punto.
- No capturan secuencias. Tu cliente no es un snapshot: es una historia de 24 meses de pagos, contactos, promesas rotas y cumplidas.
- No personalizan en tiempo real. El árbol da la misma recomendación toda la semana.
- Asumen estabilidad. En cobranzas, donde el comportamiento cambia con cada gestión, esa es una limitación seria.
El stack que sí está funcionando

🔹 Gradient Boosting (XGBoost, LightGBM, CatBoost). Sigue siendo el caballo de batalla para scoring tabular. Para PD (Probabilidad de Default — probabilidad de no pago), contactabilidad o probabilidad de pago, es la apuesta racional inicial. No lo abandonen.
🔹 Deep Learning tabular (TabNet, FT-Transformer). Cuando tienes cientos de features y datos no estructurados (transcripciones de llamada, conversaciones de WhatsApp, notas del agente), las redes profundas empiezan a ganarle al boosting.
🔹 Transformers para secuencias. Aquí está la frontera real del BTC (Best Time to Call — Mejor Momento para Llamar). El comportamiento de pago es una secuencia: día 5 abrió WhatsApp, día 12 ignoró llamada, día 18 hizo abono parcial, día 22 prometió y cumplió. Un transformer aprende la dinámica de esa secuencia, no solo el último estado. Esto cambia el juego.
🔹 Reinforcement Learning (Aprendizaje por Refuerzo). El siguiente salto para NBA (Next Best Action — Mejor Próxima Acción). Un agente que aprende qué política de contacto maximiza el recupero acumulado a 12 meses, no la conversión del próximo mensaje. Reconoce que sobre-contactar en mora temprana destruye recupero en mora intermedia. Requiere infraestructura de experimentación (bandits contextuales como mínimo), pero ya hay bancos en LATAM corriendo pilotos.
Los cuatro conviven. No es uno u otro: es un boosting que estima probabilidad de pago, un transformer que predice ventana óptima de contacto, y un agente RL que decide la secuencia de acciones a 60 días.
Lo simple detrás de lo técnico
Hipersegmentación = un segmento de uno. Donde antes la regla decía "todos los clientes con 30 días reciben llamada a las 11 AM", hoy el modelo dice "a Pedro mándale WhatsApp a las 8 PM con plan de 3 cuotas; a María llámala el sábado; a Juan no lo contactes esta semana".
El mito que hay que romper: implementar esto NO requiere comprar FICO ni SAS por siete cifras al año
Existe la idea instalada de que para hacer NBA o BTC con redes neuronales necesitas un proveedor enterprise con licencia anual de medio millón de dólares hacia arriba. La realidad de 2026 es otra.
La mayoría de los bancos y financieras en Chile y LATAM ya tienen en su nube todo lo necesario:
- Plataforma de ML (Machine Learning — Aprendizaje Automático) lista para usar. AWS SageMaker, Azure ML o GCP Vertex AI. Permiten entrenar, versionar, desplegar y monitorear modelos de gradient boosting, deep learning y transformers sin levantar infraestructura desde cero. Costo: pagas por uso, no por licencia.
- Data warehouse moderno = tu feature store. Snowflake, BigQuery, Redshift o Databricks bien organizados son tu repositorio de features. En piloto inicial no necesitas comprar Tecton ni Feast.
- Orquestación open source. Airflow o Prefect para pipelines, MLflow para tracking de experimentos, FastAPI para servir el modelo al motor de cobranza. Cero costo de licencia.
- Modelos pre-entrenados, gratis. Hugging Face para transformers de secuencia. XGBoost, LightGBM, PyTorch — están detrás del 80% de los papers académicos serios y son open source.
- APIs de LLM (Large Language Models — Modelos de Lenguaje) para datos no estructurados. Procesar transcripciones de llamada, extraer señales de mensajes WhatsApp o categorizar notas del agente con APIs de Claude, OpenAI o Gemini cuesta centavos por consulta. Hace 3 años esto era ciencia ficción.
Lo que no se reemplaza con tecnología y sí hay que invertir
- Un equipo pequeño y bueno: 2-3 científicos de datos seniors + 1 ingeniero ML. Hace más que un equipo grande sin foco técnico claro.
- Gobernanza, validación rigurosa, documentación de modelo, explicabilidad para el comité de riesgo. Eso requiere disciplina, no licencias.
- Acceso al negocio: que el gerente de cobranzas se siente con el equipo de modelos cada semana. Sin eso, el mejor modelo del mundo termina archivado.
El número incómodo: un piloto bien diseñado de NBA o BTC en LATAM cuesta entre USD 80K y 250K total (no anual), con resultados medibles en 4 a 6 meses. Esto no es un proyecto de capital de 18 meses. Es un sprint de innovación operacional.
Las plataformas enterprise tienen su rol en bancos grandes con compliance complejo. Pero usarlas como excusa para no empezar es exactamente eso: una excusa.
¿Cómo se empieza? No saltando al modelo. Entendiendo el punto de partida
Paso 1 · Gap Analysis de tu arquitectura de cobranza actual
Antes de hablar de XGBoost, transformers o RL, hay que mapear el punto de partida real. Y el primer mapeo — el más subestimado — es el de los datos.
1.1 · Auditoría de datos: el cimiento que casi nadie revisa
Ningún modelo, por sofisticado que sea, sobrevive a una mala estructura de datos. Y aquí está el agujero más grande de la cobranza moderna en Chile y LATAM:
Todos los bancos y financieras envían SMS, emails y WhatsApp masivamente. Pero la gran mayoría no es dueño de los datos que esos envíos generan.
Los logs de envío, apertura, click, respuesta y conversión quedan en el proveedor de mensajería (Twilio, Infobip, Sinch, agregadores locales). Con suerte, llegan en un FTP nocturno con un CSV agregado. Sin suerte, viven en un dashboard del proveedor que nadie consulta y que no se conecta con el data warehouse del banco.
¿Qué se pierde con eso?
- No sabes a qué hora cada cliente abre cada canal. Y eso es exactamente la materia prima del Best Time to Call.
- No sabes qué mensaje convierte para qué perfil. Y eso es exactamente lo que un transformer necesita aprender.
- No puedes correlacionar contacto con pago. Si el SMS de las 11:00 llevó al pago de las 14:30, esa señal está en dos sistemas distintos que nunca se hablan.
- No puedes hacer A/B testing real, porque los grupos de control y tratamiento viven en lógicas del proveedor, no tuyas.
El resto del gap analysis cubre las preguntas obvias:
- ¿Qué fuentes de datos tienes hoy? ¿Están integradas o viven en silos? ¿Tu CRM, core bancario, motor de cobranza y gestores externos hablan entre sí?
- ¿Tienes feature store o cada equipo recalcula las mismas variables de cero?
- ¿Qué motor de cobranza usas? ¿Permite priorización dinámica o sigue corriendo por reglas duras?
- ¿Tienes capacidad de A/B testing en producción?
- ¿Qué tan rápido despliegas un modelo nuevo: días, semanas o meses?
1.2 · Cumplimiento del nuevo Reglamento sobre Cobranza Extrajudicial
Recordemos lo que viene (Ministerio de Economía + SERNAC, consulta pública cerrada en octubre 2025, vigencia esperada 2026): máximo 1 contacto telefónico o visita por semana, máximo 2 contactos por otros medios (email, SMS, WhatsApp) separados por al menos 2 días, gestión digital obligatoria registrada y almacenada por 2 años, notificación con formato único estandarizado, y solo se pueden cobrar las gestiones efectivamente realizadas.
Este punto se conecta directamente con el anterior: la obligación de almacenar 2 años de gestiones digitales te obliga a tener los datos en casa, no en el proveedor. El que no resuelva esto antes de la vigencia, va a quedar expuesto en doble frente: regulatorio y competitivo.
Las restricciones del nuevo reglamento aumentan el valor de la hiperpersonalización. Si solo puedes contactar 1 vez por semana, ese contacto tiene que ser el correcto. No puedes desperdiciarlo en un horario que el cliente no responde, en un canal que ignora, o con un mensaje que no convierte. Y para acertar, necesitas tus propios datos — no los del proveedor.
El gap analysis completo te dice qué necesitas construir, qué ya tienes, dónde están los riesgos regulatorios y cuánto te demoras en estar listo. Es lo que evita el error más caro: empezar el modelo antes de saber si la organización tiene los datos para alimentarlo y la capacidad para ejecutar lo que recomiende.
Paso 2 · Piloto acotado
Un solo producto, una sola etapa de mora (ejemplo: BTC en mora temprana de tarjeta de crédito). Métricas claras, validación A/B rigurosa, plan de explicabilidad para el comité de riesgo desde el día uno.
Paso 3 · Industrialización progresiva
Probado el caso piloto, expansión a otros productos y etapas, gobernanza formalizada, y conexión con el motor de cobranza productivo.
Resultados típicos en proyectos bien implementados
- −30% a −40% en intentos de contacto (clave bajo el nuevo reglamento)
- +15% a +25% en recupero en mora temprana
- Liberación de capacidad operativa para casos complejos
- Mejor experiencia del cliente y menor riesgo regulatorio
El punto incómodo (y por qué los pilotos mueren)
El reporte SAS/IDC pone el dedo en la llaga. El problema no es la tecnología — existe, está documentada, y como vimos, está al alcance de cualquier banco mediano. El problema es que las instituciones hacen dos cosas mal al mismo tiempo:
- Ejecutan con técnicas obsoletas porque "siempre funcionó así".
- Cuando intentan modernizarse, lo hacen sin gobernanza, sin explicabilidad y sin validación rigurosa. La confianza interna se rompe al primer mes con malos resultados, y el proyecto muere en el segundo trimestre.
No se trata de tener el modelo más sofisticado. Se trata de tener el modelo que tu organización confíe lo suficiente como para dejarlo decidir.
¿Tu organización está en alguno de estos escenarios?
- Tienes pilotos de IA archivados que prometieron mucho y entregaron poco.
- Tu segmentación de cobranza se quedó pegada y rinde cada vez menos.
- Tienes el mandato de modernizar cobranza con un presupuesto razonable.
- Necesitas estar listo para el nuevo Reglamento sobre Cobranza Extrajudicial sin perder eficiencia.
Conversemos. 30 minutos pueden ahorrarte 6 meses de prueba y error.
📱 WhatsApp: +56 9 9047 6534
📧 [email protected]
🔗 linkedin.com/in/jorgezamoratoro/
¿Cuántos pilotos de IA tiene tu organización archivados en el último año? ¿Y cuántos murieron por mala tecnología — y cuántos por mala implementación?
#Cobranzas #RiesgoDeCrédito #IA #DeepLearning #Transformers #ReinforcementLearning #Banca #Fintech #TrustInAI #MLOps #ReglamentoCobranza